1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
|
import re
import requests
import json
from urllib.parse import quote
import pandas as pd
import hashlib
import urllib
import time
import csv
def get_Header():
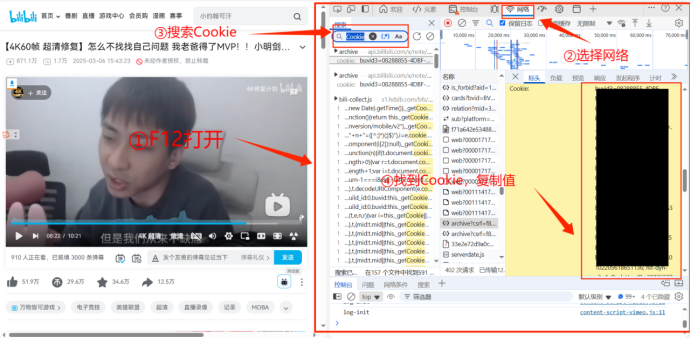
with open('bili_cookie.txt','r') as f:
cookie=f.read()
header={
"Cookie":cookie,
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0'
}
return header
def get_information(bv):
resp = requests.get(f"https://www.bilibili.com/video/{bv}/?p=14&spm_id_from=pageDriver&vd_source=cd6ee6b033cd2da64359bad72619ca8a",headers=get_Header())
obj = re.compile(f'"aid":(?P<id>.*?),"bvid":"{bv}"')
oid = obj.search(resp.text).group('id')
obj = re.compile(r'<title data-vue-meta="true">(?P<title>.*?)</title>')
try:
title = obj.search(resp.text).group('title')
except:
title = "未识别"
return oid,title
def md5(code):
MD5 = hashlib.md5()
MD5.update(code.encode('utf-8'))
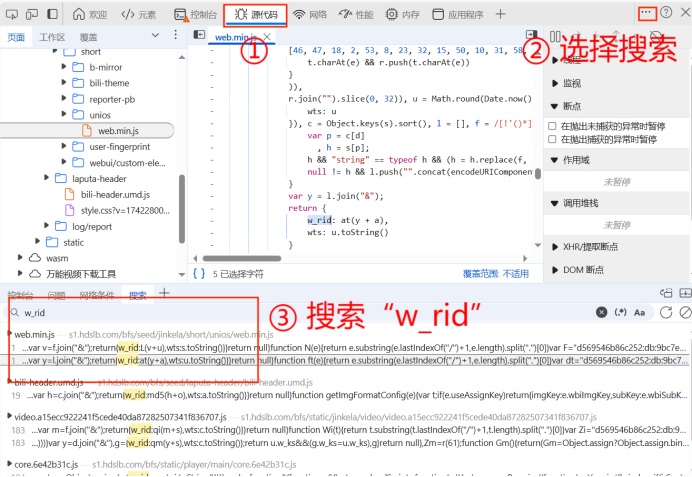
w_rid = MD5.hexdigest()
return w_rid
def start(bv, oid, pageID, count, csv_writer, is_second):
mode = 2
plat = 1
type = 1
web_location = 1315875
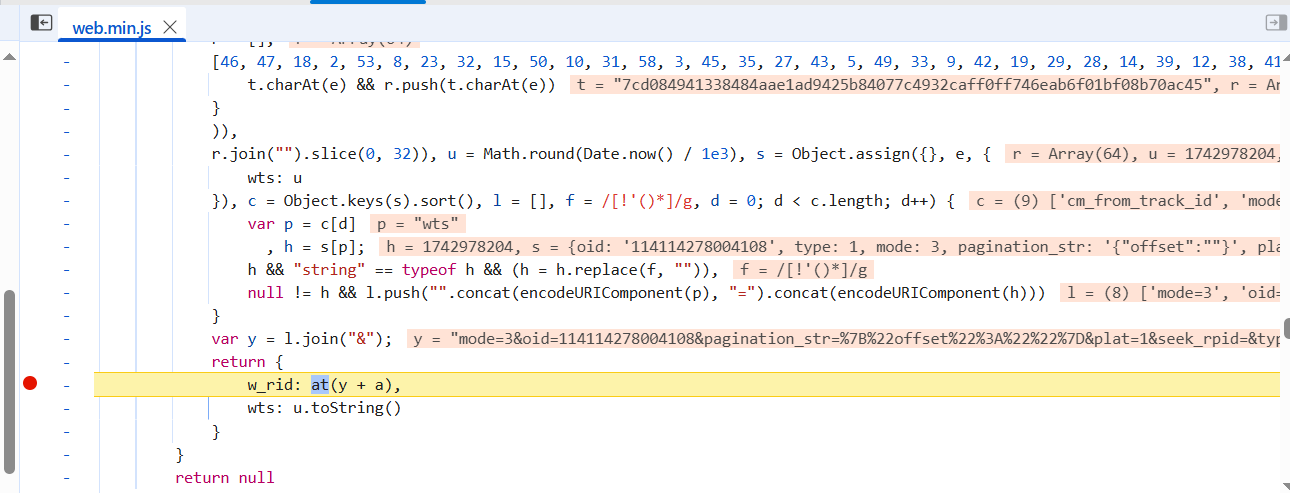
wts = int(time.time())
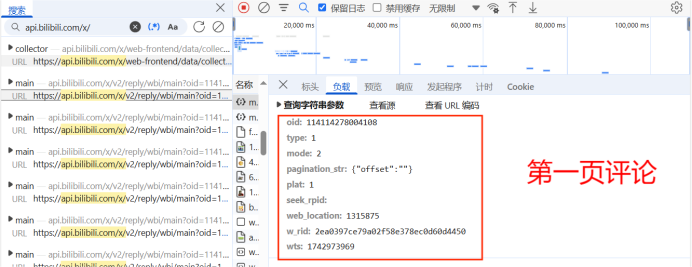
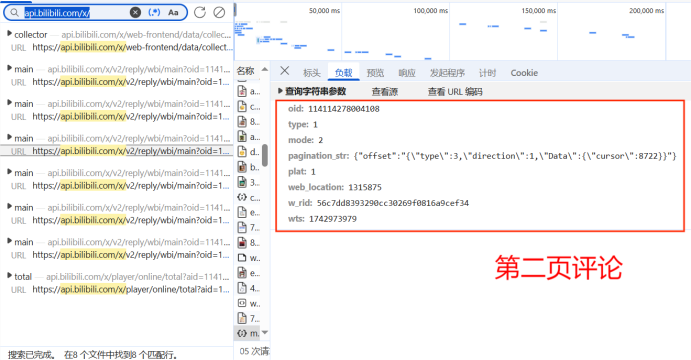
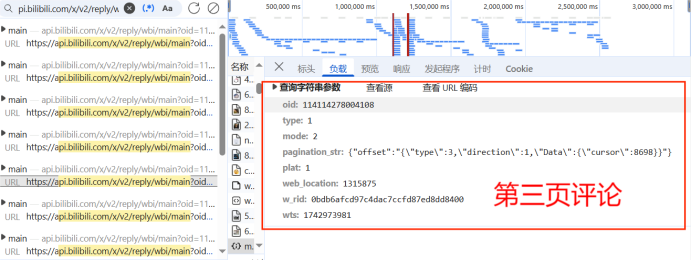
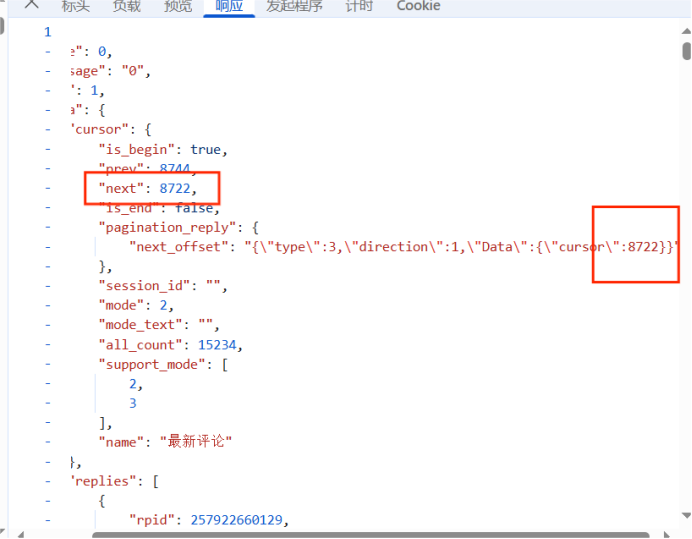
if pageID != '':
pagination_str = '{"offset":"%s"}' % pageID
code = f"mode={mode}&oid={oid}&pagination_str={urllib.parse.quote(pagination_str)}&plat={plat}&type={type}&web_location={web_location}&wts={wts}" + 'ea1db124af3c7062474693fa704f4ff8'
w_rid = md5(code)
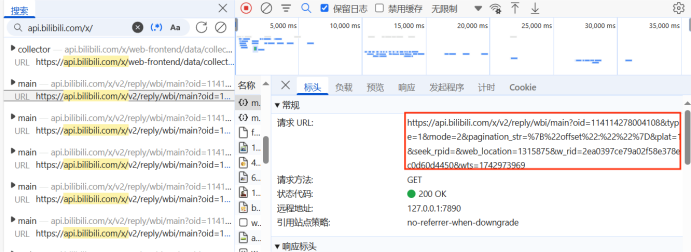
url = f"https://api.bilibili.com/x/v2/reply/wbi/main?oid={oid}&type={type}&mode={mode}&pagination_str={urllib.parse.quote(pagination_str, safe=':')}&plat=1&web_location=1315875&w_rid={w_rid}&wts={wts}"
else:
pagination_str = '{"offset":""}'
code = f"mode={mode}&oid={oid}&pagination_str={urllib.parse.quote(pagination_str)}&plat={plat}&seek_rpid=&type={type}&web_location={web_location}&wts={wts}" + 'ea1db124af3c7062474693fa704f4ff8'
w_rid = md5(code)
url = f"https://api.bilibili.com/x/v2/reply/wbi/main?oid={oid}&type={type}&mode={mode}&pagination_str={urllib.parse.quote(pagination_str, safe=':')}&plat=1&seek_rpid=&web_location=1315875&w_rid={w_rid}&wts={wts}"
comment = requests.get(url=url, headers=get_Header()).content.decode('utf-8')
comment = json.loads(comment)
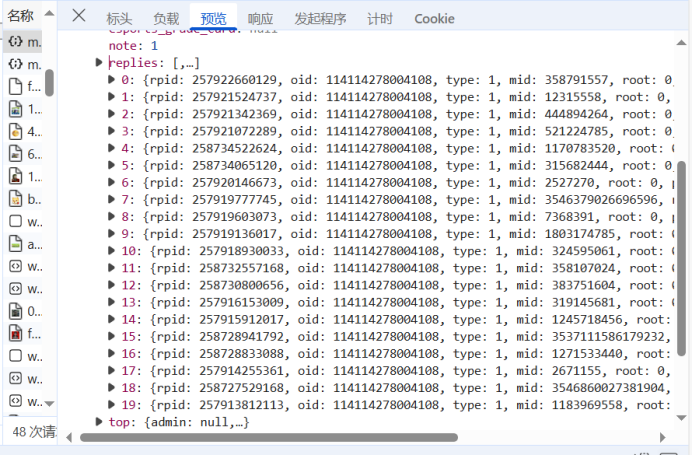
for reply in comment['data']['replies']:
count += 1
if count % 1000 ==0:
time.sleep(20)
parent=reply["parent"]
rpid = reply["rpid"]
uid = reply["mid"]
name = reply["member"]["uname"]
level = reply["member"]["level_info"]["current_level"]
sex = reply["member"]["sex"]
avatar = reply["member"]["avatar"]
if reply["member"]["vip"]["vipStatus"] == 0:
vip = "否"
else:
vip = "是"
try:
IP = reply["reply_control"]['location'][5:]
except:
IP = "未知"
context = reply["content"]["message"]
reply_time = pd.to_datetime(reply["ctime"], unit='s')
try:
rereply = reply["reply_control"]["sub_reply_entry_text"]
rereply = int(re.findall(r'\d+', rereply)[0])
except:
rereply = 0
like = reply['like']
try:
sign = reply['member']['sign']
except:
sign = ''
csv_writer.writerow([count, parent, rpid, uid, name, level, sex, context, reply_time, rereply, like, sign, IP, vip, avatar])
if is_second and rereply !=0:
for page in range(1,rereply//10+2):
second_url=f"https://api.bilibili.com/x/v2/reply/reply?oid={oid}&type=1&root={rpid}&ps=10&pn={page}&web_location=333.788"
second_comment=requests.get(url=second_url,headers=get_Header()).content.decode('utf-8')
second_comment=json.loads(second_comment)
for second in second_comment['data']['replies']:
count += 1
parent=second["parent"]
second_rpid = second["rpid"]
uid = second["mid"]
name = second["member"]["uname"]
level = second["member"]["level_info"]["current_level"]
sex = second["member"]["sex"]
avatar = second["member"]["avatar"]
if second["member"]["vip"]["vipStatus"] == 0:
vip = "否"
else:
vip = "是"
try:
IP = second["reply_control"]['location'][5:]
except:
IP = "未知"
context = second["content"]["message"]
reply_time = pd.to_datetime(second["ctime"], unit='s')
try:
rereply = second["reply_control"]["sub_reply_entry_text"]
rereply = re.findall(r'\d+', rereply)[0]
except:
rereply = 0
like = second['like']
try:
sign = second['member']['sign']
except:
sign = ''
csv_writer.writerow([count, parent, second_rpid, uid, name, level, sex, context, reply_time, rereply, like, sign, IP, vip, avatar])
try:
next_pageID = comment['data']['cursor']['pagination_reply']['next_offset']
except:
next_pageID = 0
if next_pageID == 0:
print(f"评论爬取完成!总共爬取{count}条。")
return bv, oid, next_pageID, count, csv_writer,is_second
else:
time.sleep(0.5)
print(f"当前爬取{count}条。")
return bv, oid, next_pageID, count, csv_writer,is_second
if __name__ == "__main__":
bv = "BV1ex7VzREZ8"
oid,title = get_information(bv)
next_pageID = ''
count = 0
is_second = True
with open(f'{title[:12]}_评论.csv', mode='w', newline='', encoding='utf-8-sig') as file:
csv_writer = csv.writer(file)
csv_writer.writerow(['序号', '上级评论ID','评论ID', '用户ID', '用户名', '用户等级', '性别', '评论内容', '评论时间', '回复数', '点赞数', '个性签名', 'IP属地', '是否是大会员', '头像'])
while next_pageID != 0:
bv, oid, next_pageID, count, csv_writer,is_second=start(bv, oid, next_pageID, count, csv_writer,is_second)
|



 微信打赏
微信打赏 支付宝打赏
支付宝打赏






