内容
访问豆瓣电影Top250(https://movie.douban.com/top250?start=0)
导入库
1 2 from bs4 import BeautifulSoup as BSimport requests
打开文件和设置请求头
1 2 3 4 fs = open ("豆瓣.txt" , 'w' , encoding='utf-8' ) headers = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36" }
fs:打开(或创建)一个名为“豆瓣.txt”的文件,用于写入数据,文件编码设置为utf-8。
headers:设置HTTP请求头,模拟浏览器访问,User-Agent是浏览器标识,有助于避免被网站识别为爬虫。
爬取豆瓣电影Top 250
1 2 3 for page in range (0 , 250 , 25 ): soup = BS(requests.get(f"https://movie.douban.com/top250?start={page} &filter=" , headers=headers).content.decode("utf-8" ), "lxml" ) content = soup.select('#content > div > div.article > ol > li > div > div.info' )
for循环:遍历豆瓣电影Top 250的页面,每页25部电影,共10页(0到250,步长为25)。
requests.get:发送GET请求到豆瓣电影Top 250的URL,start={page}参数用于指定页面的起始索引。
BS:创建一个BeautifulSoup对象来解析请求返回的HTML内容,使用lxml作为解析器。
select:使用CSS选择器找到包含电影信息的HTML元素。
提取电影信息并写入文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 for i in content: name = "电影:" + i.select('.title' )[0 ].text url = i.find('a' )['href' ] sp = BS(requests.get(url, headers=headers).content.decode("utf-8" ), "lxml" ) mainer = i.find('p' ) mainer = mainer.text.strip() writers = sp.select('#info > span' ) writers = writers[1 ].text all_time = sp.select('span[property="v:runtime"]' ) all_time = "时长:" + all_time[0 ].text number = i.find_all('span' ) number = "评分人数:" + number[-2 ].text brief = sp.select('span[property="v:summary"]' ) brief = "简介:" + brief[0 ].text all = name + "\n" + mainer + "\n" + writers + "\n" + all_time + "\n" + number + "\n" + brief + "\n"
内层for循环:遍历每页中的电影信息。
name:提取电影名称。
url:找到电影链接的href属性。
sp:发送请求到电影的详细页面,并创建一个BeautifulSoup对象来解析HTML。
mainer:提取导演、主演、类型、上映时间信息。
writers:提取编剧信息。
all_time:提取片长信息。
number:提取评分人数信息。
brief:提取电影简介。
all:将所有信息拼接成一个字符串。
写入文件
1 2 fs.write(all + '\n\n' ) fs.close()
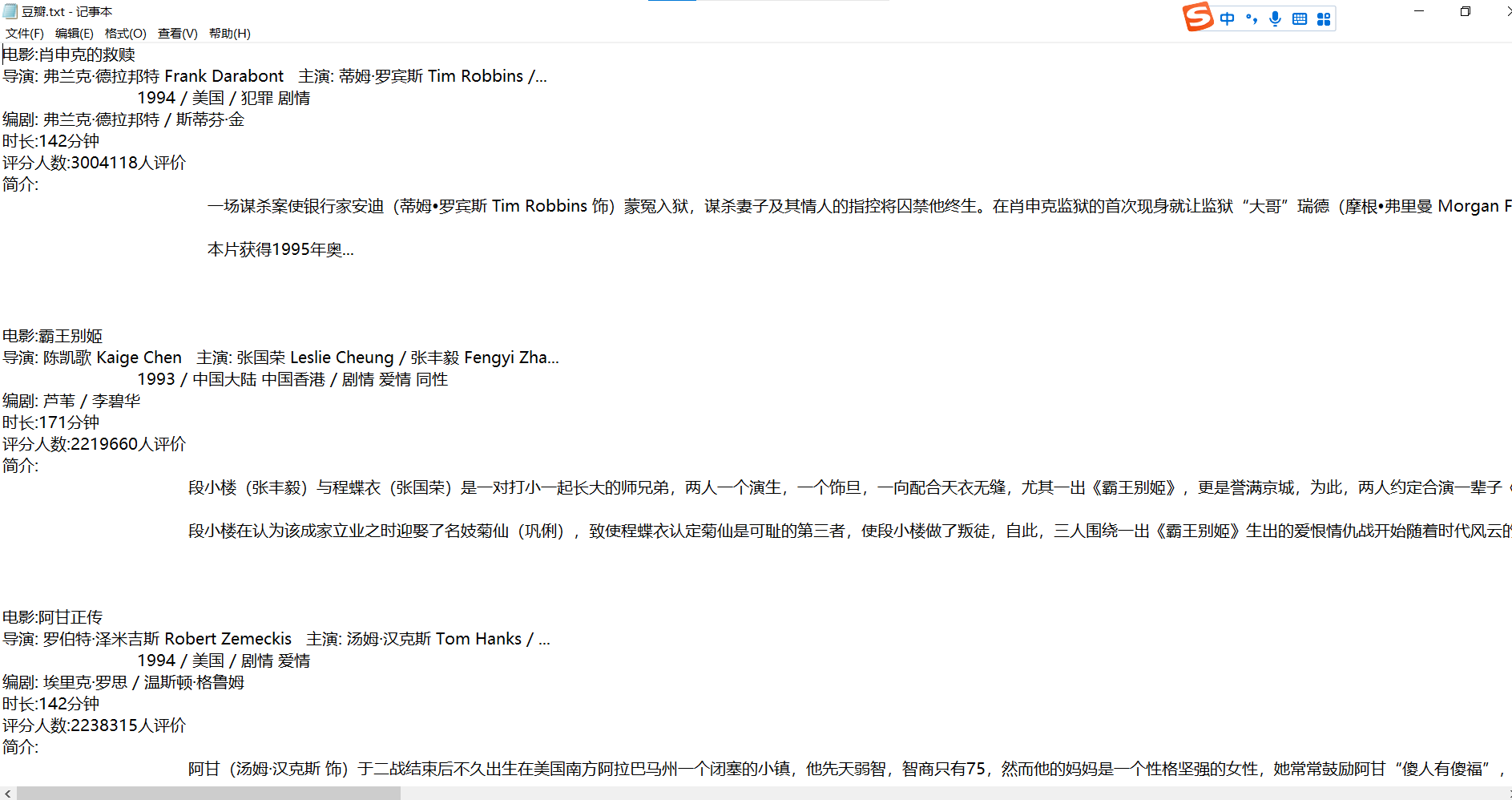
运行结果