1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
|
import requests
import json
from datetime import datetime
import csv
import time
count=0
def add_count():
global count
count +=1
def get_header():
with open("weibo_cookie.json",'r') as f:
header=json.loads(f.read())
header['referer']='https://weibo.com/'
return header
def get_keyword(url):
list = url.split('/')
return list[-2],url_to_mid(list[-1])
def decode_base62(b62_str):
charset = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
base = 62
num = 0
for c in b62_str:
num = num * base + charset.index(c)
return num
def url_to_mid(url):
result = ''
for i in range(len(url), 0, -4):
start = max(i - 4, 0)
segment = url[start:i]
num = str(decode_base62(segment))
if start != 0:
num = num.zfill(7)
result = num + result
return int(result)
def get_name(uid):
url = f"https://weibo.com/ajax/profile/info?custom={uid}"
return json.loads(requests.get(url=url,headers=get_header()).content.decode('utf-8'))['data']['user']['screen_name']
def get_age(birthday):
birth = datetime.strptime(birthday, "%Y-%m-%d")
today = datetime.today()
return today.year - birth.year - ((today.month, today.day) < (birth.month, birth.day))
def get_user_info(uid):
url = f"https://weibo.com/ajax/profile/info?uid={uid}"
data = json.loads(requests.get(url=url,headers=get_header()).content.decode('utf-8'))['data']['user']
followers_count = data['followers_count']
friends_count = data['friends_count']
try:
total_cnt = data['status_total_counter']['total_cnt']
total_cnt = int(total_cnt.replace(",", ""))
except:
total_cnt = ''
try:
description = data['description']
except:
description = ''
if data['verified'] == True:
verified = '是'
else:
verified = '否'
try:
gender = data['gender']
if gender == 'm':
gender = '男'
elif gender == 'f':
gender = '女'
else:
gender = '未知'
except:
gender = '未知'
try:
svip = data['svip']
except:
svip = ''
url = f"https://weibo.com/ajax/profile/detail?uid={uid}"
data = json.loads(requests.get(url=url,headers=get_header()).content.decode('utf-8'))['data']
try:
age = data['birthday'].split(' ')[0]
age = get_age(age)
except:
age = ''
try:
constellation = data['birthday'].split(' ')[1]
except:
constellation = ''
try:
weibo_created = data['created_at']
except:
weibo_created = ''
try:
school = data['education']['school']
except:
school = ''
try:
career = data['career']['company']
except:
career = ''
try:
desc_text = data['desc_text']
except:
desc_text = ''
try:
user_location = data['ip_location'][5:]
except:
user_location = '其他'
try:
sunshine_credit = data['sunshine_credit']['level'][2:]
except:
sunshine_credit =''
return followers_count,friends_count,total_cnt,user_location,description,verified,gender,svip,age,constellation,weibo_created,school,career,desc_text,sunshine_credit
def get_data(data):
idstr = data['idstr']
rootidstr = data['rootidstr']
created_at = data['created_at']
dt = datetime.strptime(created_at, "%a %b %d %H:%M:%S %z %Y")
created_at = dt.strftime("%Y-%m-%d %H:%M:%S")
screen_name = data['user']['screen_name']
user_id = data['user']['id']
text_raw = data['text_raw']
like = data['like_counts']
try:
total_number = data['total_number']
except:
total_number = 0
com_source = data['source'][2:]
fan={
'1':'铁粉',
'2':'金粉',
'3':'钻粉'
}
try:
icon_url = data['user']['fansIcon']['icon_url']
fansIcon = f"{fan[icon_url[-7]]}{icon_url[-5]}"
except:
fansIcon = ''
followers_count,friends_count,total_cnt,user_location,description,verified,gender,svip,age,constellation,weibo_created,school,career,desc_text,sunshine_credit = get_user_info(user_id)
return idstr,created_at,screen_name,user_id,text_raw,like,com_source,total_number,rootidstr,fansIcon,followers_count,friends_count,total_cnt,user_location,description,verified,gender,svip,age,constellation,weibo_created,school,career,desc_text,sunshine_credit
def get_information(uid,mid,max_id,fetch_level):
if max_id == '':
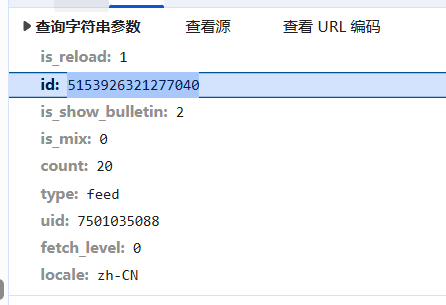
url = f"https://weibo.com/ajax/statuses/buildComments?flow=1&is_reload=1&id={mid}&is_show_bulletin=2&is_mix=0&count=20&uid={uid}&fetch_level={fetch_level}&locale=zh-CN"
else:
url = f"https://weibo.com/ajax/statuses/buildComments?flow=1&is_reload=1&id={mid}&is_show_bulletin=2&is_mix=0&max_id={max_id}&count=20&uid={uid}&fetch_level={fetch_level}&locale=zh-CN"
resp = json.loads(requests.get(url=url,headers=get_header()).content.decode('utf-8'))
datas = resp['data']
for data in datas:
add_count()
idstr,created_at,screen_name,user_id,text_raw,like,com_source,total_number,rootidstr,fansIcon,followers_count,friends_count,total_cnt,user_location,description,verified,gender,svip,age,constellation,weibo_created,school,career,desc_text,sunshine_credit = get_data(data)
if fetch_level == 0:
rootidstr = ''
csv_writer.writerow([count,idstr,rootidstr,user_id,created_at,screen_name,gender,text_raw,like,total_number,fansIcon,com_source,user_location,description,desc_text,verified,svip,age,constellation,school,career,weibo_created,sunshine_credit,followers_count,friends_count,total_cnt])
time.sleep(0.5)
if total_number >0 and fetch_level == 0:
get_information(uid,idstr,0,1)
print(f"当前爬取:{count}条")
max_id = resp['max_id']
if max_id != 0:
get_information(uid,mid,max_id,fetch_level)
else:
return
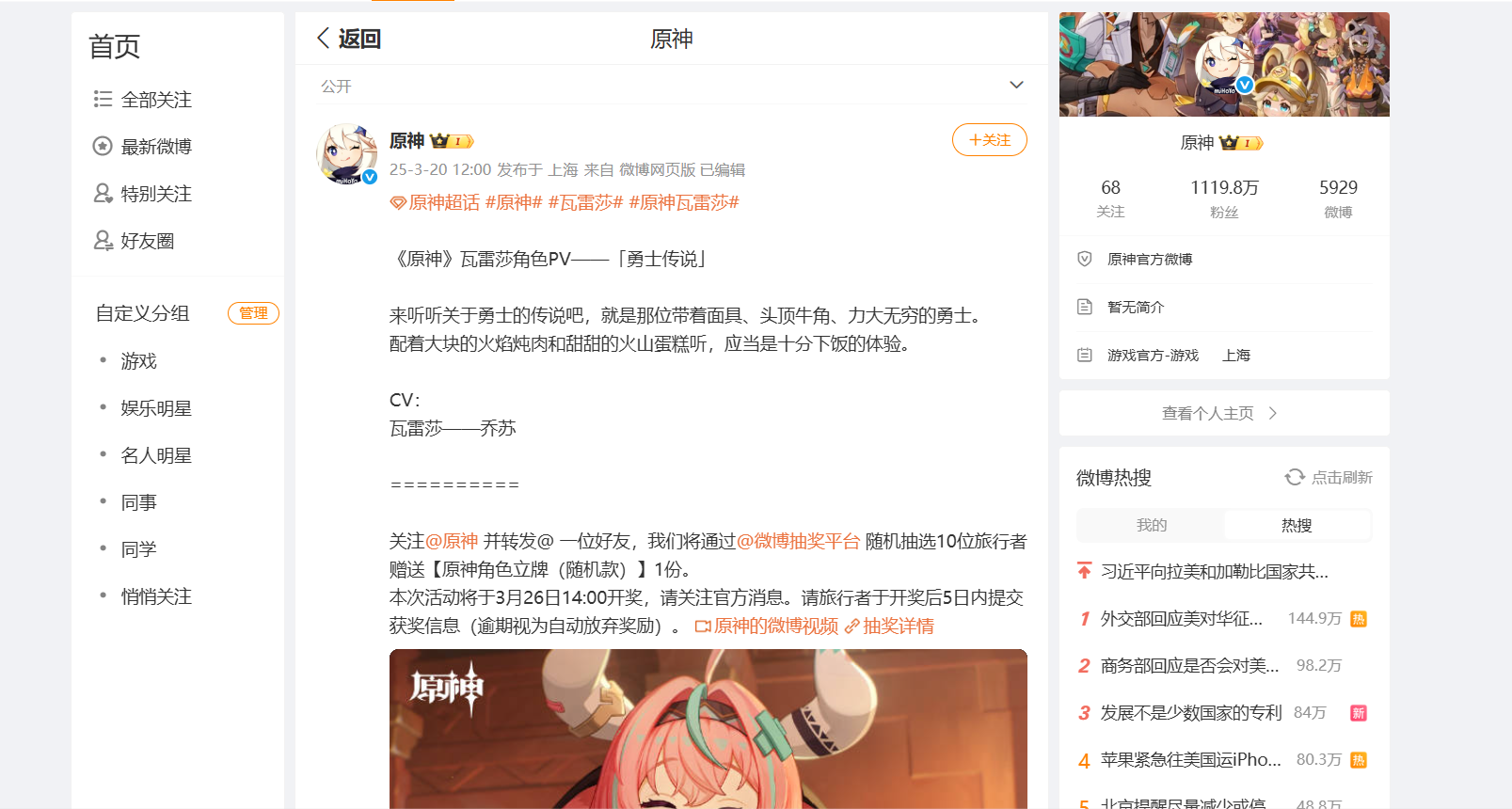
if __name__ == "__main__":
start = time.time()
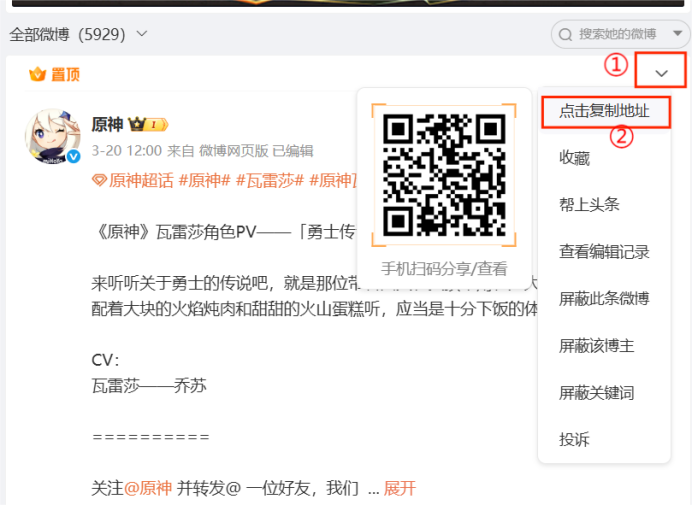
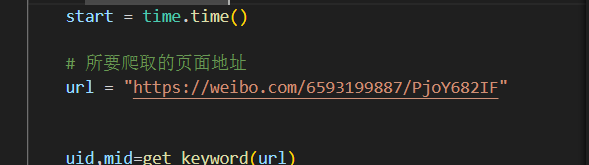
url = "https://weibo.com/6593199887/PjoY682IF"
uid,mid=get_keyword(url)
print(f"\n创建csv表中...\n创建 {get_name(uid)}_{url.split('/')[-1]}_评论(Max版) ....")
with open(f'./MaxData/{get_name(uid)}_{url.split('/')[-1]}_评论(Max版).csv', mode='w', newline='', encoding='utf-8-sig') as file:
csv_writer = csv.writer(file)
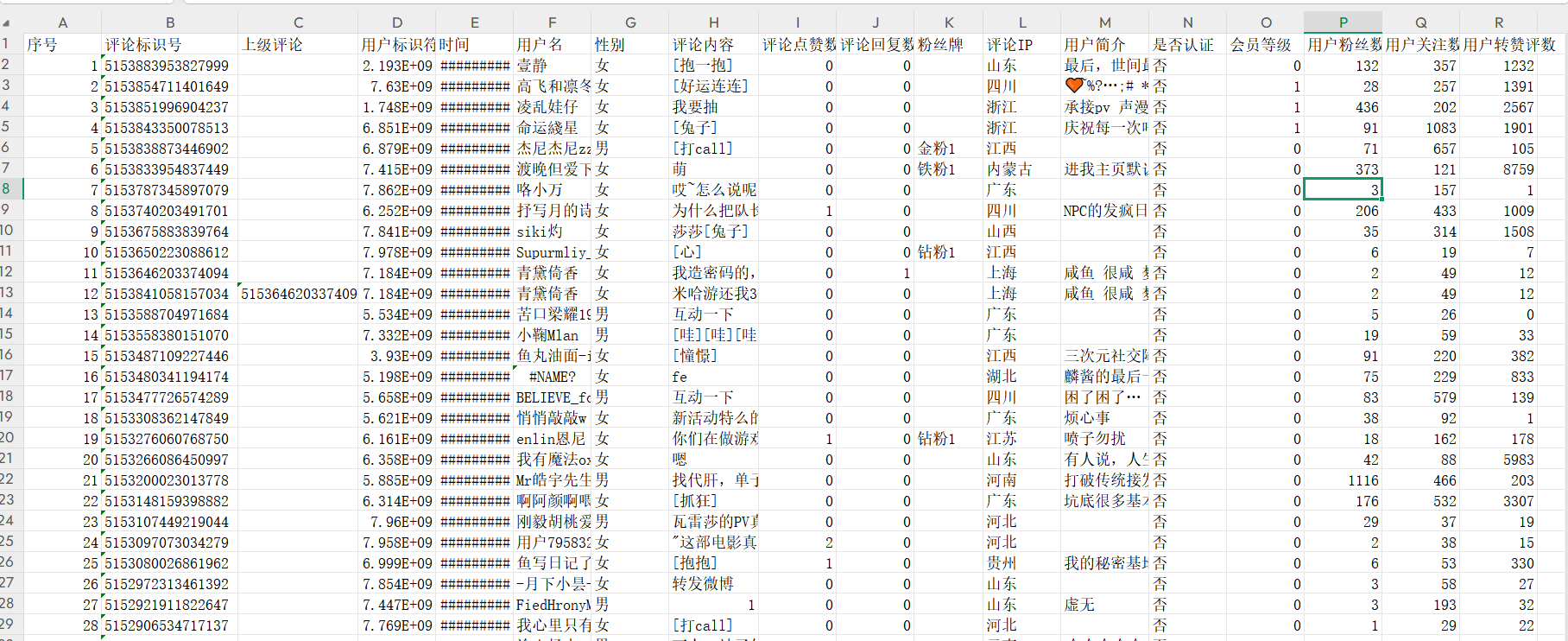
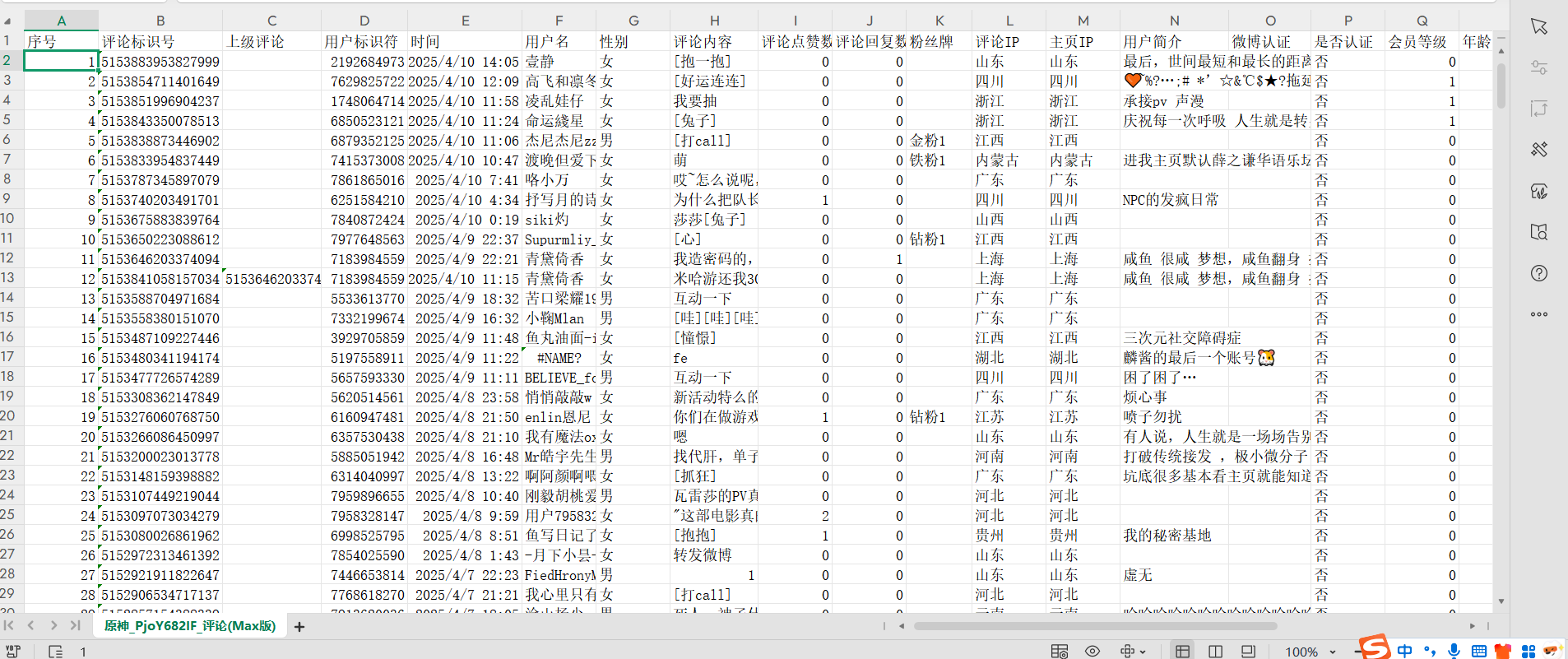
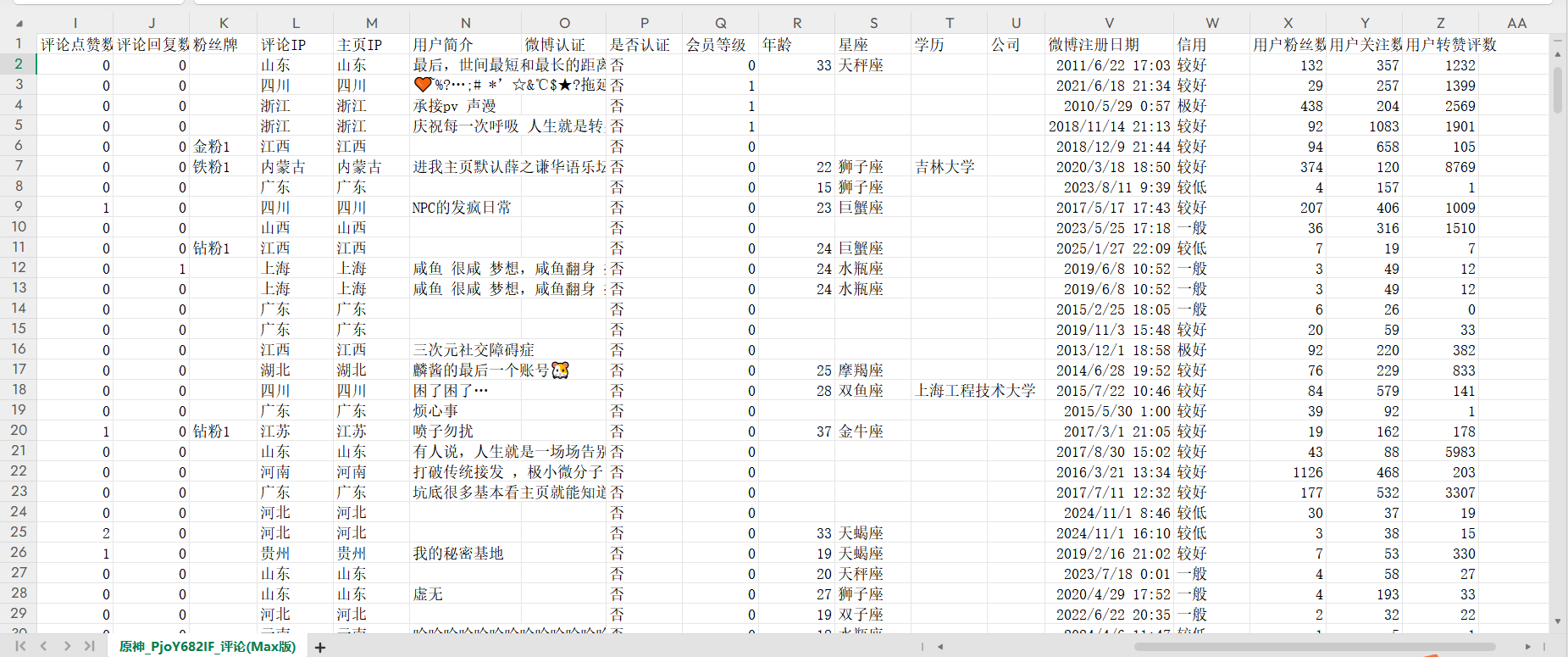
csv_writer.writerow(['序号','评论标识号','上级评论','用户标识符','时间','用户名','性别','评论内容','评论点赞数','评论回复数','粉丝牌','评论IP','主页IP','用户简介','微博认证','是否认证','会员等级','年龄','星座','学历','公司','微博注册日期','信用','用户粉丝数','用户关注数','用户转赞评数'])
get_information(uid,mid,'',0)
print(f"评论爬取完成,共计{count}条,耗时{(time.time()-start)/60:.2f}分")
|

 微信打赏
微信打赏 支付宝打赏
支付宝打赏






